動機
私は去年の 12 月からパーソナルジムに通い始めました。
トレーナーさんが毎回手書きでトレーニング記録を付けてくれているのですが、これをデータ化して進捗を可視化したいと思いました。
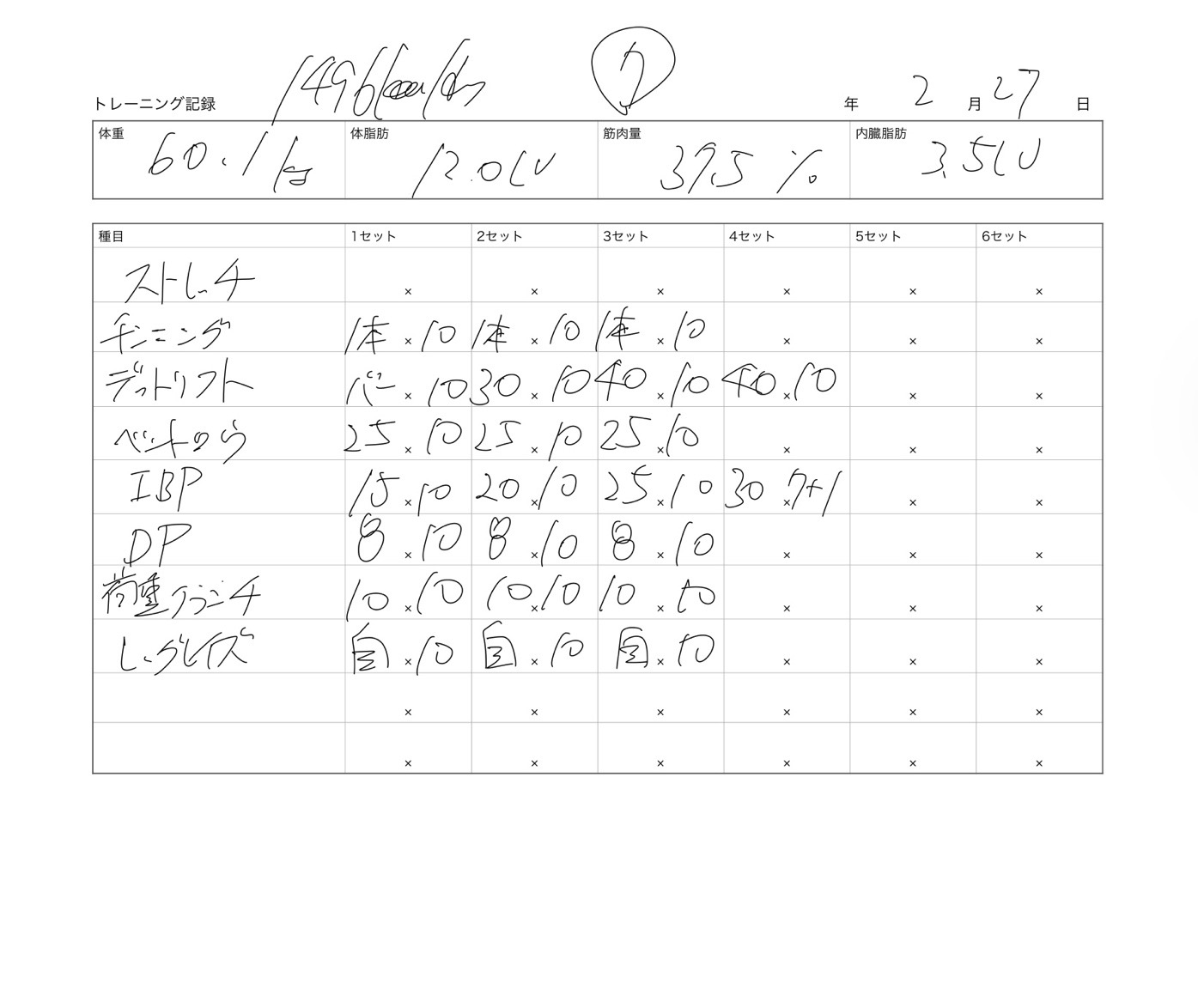
こちらがトレーニング記録です。
正直なんて書いてあるのか分からない部分もあるのですが、これは元々トレーナーさんが個人的に記録していたものを私が「スクショ送ってくれませんか?」と無理矢理お願いしたものなので文句は言えません。
やりたいこと
人間が Google Drive に画像をアップロードしたら自動で Spreadsheet に書き込まれる。
- 画像を Google Drive にアップロードする (人間)
- 定期的に Google Drive を監視して追加された画像を取得する (n8n)
- 画像を OCR で JSON 化する (Gemini, Mastra)
- Google Spreadsheet に書き込む (n8n)
- グラフ化して可視化する
OCR にどの AI を使うか
検討したのは以下です。
- OpenAI
- Google Gemini
- Mistral OCR
Mistral OCR はかなり精度が良いということで期待していたのですが、日本語の手書き文字には弱いようで文字起こしすらしてくれませんでした。
少し試した中で gpt-4o は 数字の認識精度が悪い印象だったため今回は Gemini を選択しました。
ちなみに少しだけ試した gpt-4.5-preview は手直しの必要が無いくらい精度が良かったですが料金の関係でやめました。
Google Colaboratory で試作する
まずは prompt の調整と精度を確認するために Google Colaboratory で試作しました。
ただ画像を渡しただけでは思うような結果を返してくれなかったので、prompt で無理矢理制御しました。
特に種目名の抽出にかなりばらつきがあったのでこちらで事前に候補を与えそれに近しいものを選ばせるようにしました。
またレスポンスの型はこちらで定義すればその通りに返してくれましたが、そのままだと
```json``` で囲まれた文字列が返されます。config で
response_mime_type を application/json にすることで JSON 形式で返してくれました。import os
from google import genai
from PIL import Image
import json
from google.colab import files
from google.colab import auth
from google.auth import default
from google.colab import userdata
import gspread
auth.authenticate_user()
creds, _ = default()
gc = gspread.authorize(creds)
google_api_key = userdata.get('google_api_key')
client = genai.Client(api_key=google_api_key)
prompt = """
画像はトレーニングの記録を記載された画像です。
1. トレーニングの内容を以下のルールに従って抽出してください。
- {種目名} は単一のテキストです
- {種目名} ごとの記録は必ず {重量} × {回数} です
- 「→」は前回の記録と同様ということを表現しています。「→」という記号を使わずに表現してください
- {重量} と {回数} は必ず整数です
- {重量} に 数値以外の文字列が使われる場合があります。これは 0 として扱ってください。例: 「バー」「自」
- {重量} は「1本」など数字と単位の組み合わせである場合があります。これは数字のみを抽出してください
- {回数} は必ず一桁か二桁です
- {種目名} = ストレッチ は除外してください
- {種目名} は下記の配列に含まれている文字列である可能性が高いです
- ['ブルガリアン', 'チンニング', 'ランジ', 'サイドレイズ', 'Tバーロウ', 'Vシット', 'アブローラー', 'デッドリフト', 'ベントロウ', 'クランチ', '重荷クランチ', 'レッグレイズ', 'ラットプル', 'ケーブルクランチ', 'ケーブルオーバー', 'ハンギングレッグレイズ', 'TRXサイドプランク', 'TRXプル', 'TRXクライマー', 'ダンベルワイドスクワット', 'ワイドスクワット', 'シーテッドロウ', 'ワンハンドロウ', 'アーノルドプレス', 'インクラインカール', 'BP', 'DP', 'IBP', 'DSP']
- あなたが解釈した {種目名} をそのまま menu.nameSource に設定してください
- 記載が無いセットは除外してください
- あなたが解釈したテキストを {重量} x {回数} の形式で menu.records.text に設定してください
- 解析結果が誤っている、外れ値の可能性がある場合は isSuspected に true を設定してください
2. 日付や体重などの情報を以下のルールに従って抽出してください。
- 体重の単位は kg です
- 体脂肪と筋肉量の単位は % です
- 内臓脂肪の単位は v です
- それぞれ小数点を含みます
- 日付は YYYY/MM/DD の形式で表現してください
- 12月の場合のみ2024年として扱ってください
3. アウトプットは以下の JSON schema に従って JSON を出力してください。
Meta = {'date': str, 'bodyWeight': float, 'bodyFat': float, 'muscleMass': float, 'visceralFat': float}
Menu = {'name': str, 'nameSource': str, 'records': [{'weight': int, 'count': int, 'text': str, 'isSuspected': bool}]
Return: list[{...Meta, menu: list[Menu]}]
"""
def main(image, imageUrl):
response = client.models.generate_content(
model='gemini-2.0-flash',
contents=[image, prompt],
config={
'response_mime_type': 'application/json'
}
)
print(response.model_dump_json(exclude_none=True, indent=4))
try:
data = json.loads(response.text)
except json.JSONDecodeError as e:
print("JSON decode error:", e)
data = []
ss = gc.open_by_key('xxxx')
st_meta = ss.get_worksheet_by_id('0')
st_records = ss.get_worksheet_by_id('xxxx')
# スプレッドシートにデータを書き込み
for entry in data:
date = entry["date"]
bodyWeight = entry["bodyWeight"]
bodyFat = entry["bodyFat"]
muscleMass = entry["muscleMass"]
visceralFat = entry["visceralFat"]
existing_dates = st_meta.col_values(1)
if date not in existing_dates:
meta_row = [date, bodyWeight, bodyFat, muscleMass, visceralFat, imageUrl, json.dumps(data)]
st_meta.append_row(meta_row, value_input_option='USER_ENTERED')
else:
print(f"日付 {date} は既に存在します。スキップします。")
for menu in entry["menu"]:
menu_name = menu["name"]
menu_name_source = menu["nameSource"]
for record in menu["records"]:
weight = record["weight"]
count = record["count"]
text = record["text"]
is_suspected = record["isSuspected"]
records_row = [date, menu_name, menu_name_source, weight, count, text, is_suspected]
st_records.append_row(records_row, value_input_option='USER_ENTERED')
print("スプレッドシートへの書き込みが完了しました。")
from kora.xattr import get_id
folder_path = '/content/drive/MyDrive/training_record'
images = [f for f in os.listdir(folder_path) if f.endswith('.JPG')]
for image_filename in images:
image_path = os.path.join(folder_path, image_filename)
image = Image.open(image_path)
fid = get_id(image_path)
drive_path = "https://drive.google.com/drive/u/0/folders/{}".format(fid)
main(image, drive_path)Mastra を使ってみる
Mastra は TypeScript 用の AI エージェントフレームワークです。
Agents と Workflows を使い、画像を受け取って OCR を実行し JSON を返すというところまでを実装します。
Agents
まずは OCR 専用の Agent を作成します。
プロンプトは Google Colaboratory で試作したものとほとんど同じですが、課題だった日付の年をどう取得するかについてはファイル名から取得するようにしました。
import { google } from '@ai-sdk/google'
import { Agent } from '@mastra/core/agent'
const prompt = `
画像はトレーニングの記録を記載された画像です。
1. トレーニングの内容を以下のルールに従って抽出してください。
- {種目名} は単一のテキストです
- {種目名} ごとの記録は必ず {重量} × {回数} です
- 「→」は前回の記録と同様ということを表現しています。「→」という記号を使わずに表現してください
- {重量} と {回数} は必ず整数です
- {重量} に 数値以外の文字列が使われる場合があります。これは 0 として扱ってください。例: 「バー」「自」
- {重量} は「1本」など数字と単位の組み合わせである場合があります。これは数字のみを抽出してください
- {回数} は必ず一桁か二桁です
- {種目名} = ストレッチ は除外してください
- {種目名} は下記の配列に含まれている文字列である可能性が高いです
- ['ブルガリアン', 'チンニング', 'ランジ', 'レッグレイズ', 'サイドレイズ', 'Tバーロウ', 'Vシット', 'アブローラー', 'デッドリフト', 'ベントロウ', 'クランチ', '荷重クランチ', 'ラットプル', 'ケーブルクランチ', 'ケーブルプリーチャーカール', 'ケーブルクロスオーバー', 'ハンギングレッグレイズ', 'TRXサイドプランク', 'TRXプル', 'TRXクライマー', 'ダンベルワイドスクワット', 'ワイドスクワット', 'シーテッドロウ', 'ワンハンドロウ', 'アーノルドプレス', 'インクラインカール', 'BP', 'DP', 'IBP', 'DSP']
- あなたが解釈した {種目名} をそのまま menu.nameSource に設定してください
- ひらがなの「し」は「レ」である可能性が高いです
- 記載が無いセットは除外してください
- あなたが解釈した重量と回数のテキストをそのまま menu.records.text に設定してください
- 解析結果が誤っている、外れ値の可能性がある場合は isSuspected に true を設定してください
- セット数を menu.records.set に設定してください
- セット数は 1 から始まります
2. 日付や体重などの情報を以下のルールに従って抽出してください。
- 体重の単位は kg です
- 体脂肪と筋肉量の単位は % です
- 内臓脂肪の単位は v です
- それぞれ小数点を含みます
- 日付はファイル名から取得してください
- YYYY/MM/DD の形式で表現してください
3. Use this JSON schema:
Meta = {'date': str, 'bodyWeight': float, 'bodyFat': float, 'muscleMass': float, 'visceralFat': float}
Menu = {'name': str, 'nameSource': str, 'records': [{'set': int, 'weight': int, 'count': int, 'text': str, 'isSuspected': bool}]
Return: {...Meta, menu: list[Menu]}
`
export const ocrAgent = new Agent({
name: 'OCR Agent',
instructions: prompt,
model: google('gemini-2.0-flash-001')
})API キーは環境変数に設定されたもの (
OPENAI_API_KEY, ANTHROPIC_API_KEY, GOOGLE_GENERATIVE_AI_API_KEY) を勝手に取得してくれますが、もし Agent ごとに別の API キーを使いたい場合は以下のように指定することも出来ます。import { createGoogleGenerativeAI } from '@ai-sdk/google'
export const google = createGoogleGenerativeAI({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY_2
})
export const fooAgent = new Agent({
name: 'Foo Agent',
instructions: prompt,
model: google('gemini-2.0-flash-001')
})Workflows
次に OCR を実行し JSON を返す一連の処理を行うための Workflow を作成します。
Workflow は複数の Step から構成されます。
この記事を書くまでは 「Agent を実行する Step」と「JSON にパースする Step」の 2 つに分けていたのですが、呼び出し側で Agent の output の型を制御出来ることに気づいたので 1 つだけになりました。
https://mastra.ai/docs/agents/00-overview#3-structured-output
ちなみに Step 間のデータの受け渡しについて、 Example では
context.steps.stepOne.output のような書き方をすることが多いですが、これだと型が効かないため inputSchema を定義し variables で明示的に渡すと良いです。詳しくは以下に書いてあります。
https://mastra.ai/docs/workflows/variables
import { Step, Workflow } from '@mastra/core/workflows'
import { z } from 'zod'
const outputResultSchema = z.object({
date: z.string(),
bodyWeight: z.number(),
bodyFat: z.number(),
muscleMass: z.number(),
visceralFat: z.number(),
menu: z.array(
z.object({
name: z.string(),
nameSource: z.string(),
records: z.array(
z.object({
set: z.number(),
weight: z.number(),
count: z.number(),
text: z.string(),
isSuspected: z.boolean()
})
)
})
)
})
const ocrStep = new Step({
id: 'ocr-step',
description: '画像を受け取り、OCR を実行して JSON テキストを返す',
inputSchema: z.object({
fileUrl: z.string(),
filename: z.string()
}),
outputSchema: outputResultSchema,
execute: async ({ context, mastra }) => {
const filename = context.inputData.filename
const imageUrl = context.inputData.fileUrl
// convert to base64
const image = await fetch(imageUrl)
.then((res) => res.arrayBuffer())
.then((buffer) => {
const base64 = Buffer.from(buffer).toString('base64')
return `data:image/jpeg;base64,${base64}`
})
const res = await mastra?.getAgent('ocrAgent').generate(
[
{
role: 'user',
content: [
{
type: 'image',
image: image,
mimeType: 'image/jpeg'
}
]
},
{
role: 'user',
content: [
{
type: 'text',
text: `filename: ${filename}`
}
]
}
],
{
output: outputResultSchema
}
)
if (!res?.object) {
throw new Error('OCR failed')
}
return res.object
}
})
export const ocrWorkflow = new Workflow({
name: 'OCR Workflow',
triggerSchema: z.object({
fileUrl: z.string(),
filename: z.string()
})
})
ocrWorkflow
.step(ocrStep, {
variables: {
fileUrl: {
step: 'trigger',
path: 'fileUrl'
},
filename: {
step: 'trigger',
path: 'filename'
}
}
})
.commit()n8n で自動化する
n8n では以下のことを行います。
- Google Drive のフォルダを定期的にチェックする
- 新しい画像が追加されたら Mastra の Workflow を実行する
- 取得した JSON を Google Spreadsheet に書き込む
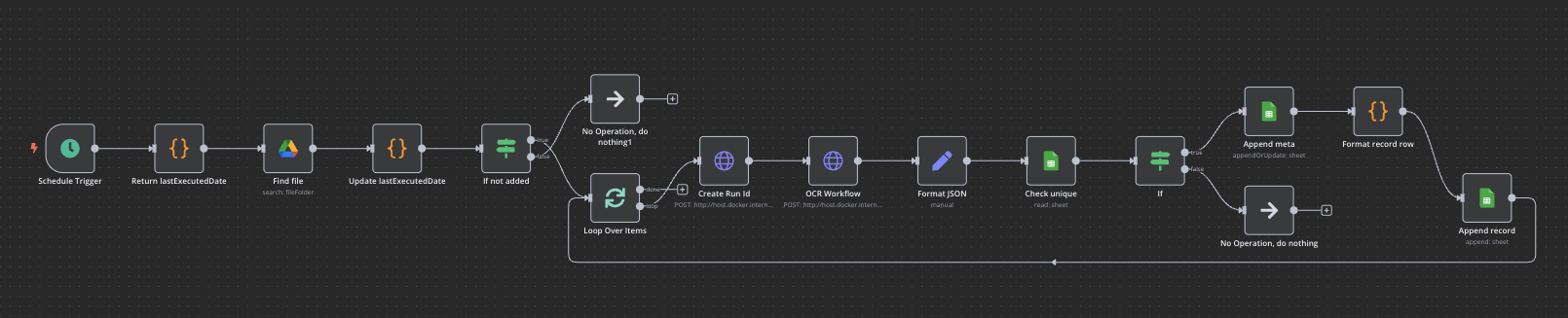
Workflow の全体図
Google Drive から画像を取得する
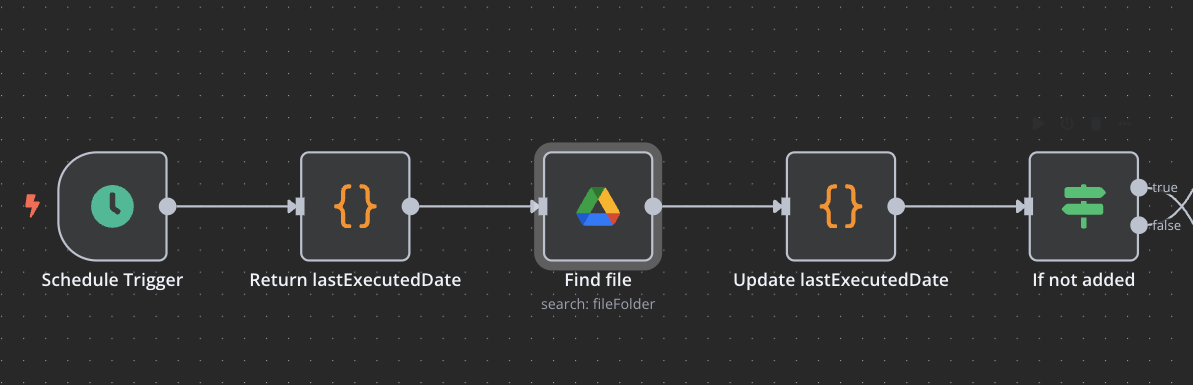
n8n では Google Drive と連携するためのノードが用意されています。
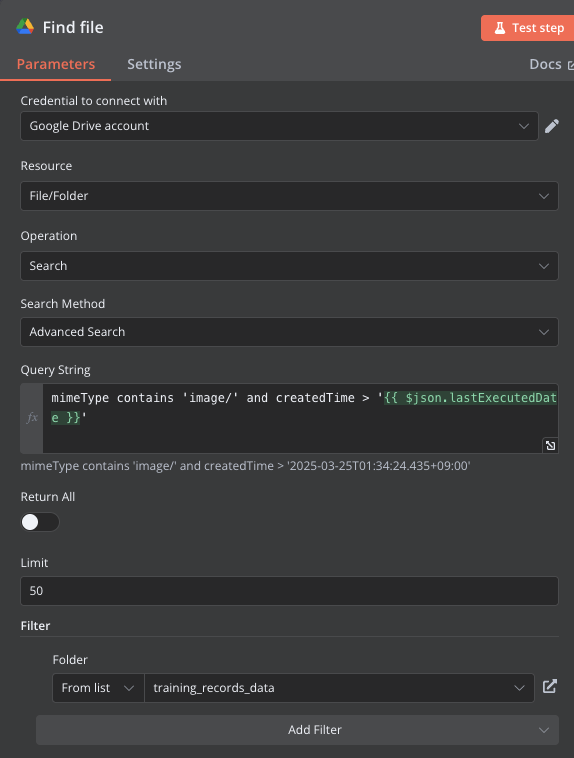
フォルダを監視し変更があれば実行するトリガーもあるのですが、複数ファイルが追加されたときに最新の一つしか取得出来なかったので今回は通常の Schedule Trigger を使いました。
1 分ごとに実行し、実行日時以降に追加されたファイルを取得します。
また最後に実行した日時を保存しておき、次回実行時はそれを使うようにしています。
$getWorkflowStaticData('global') を使うことでその workflow 内にデータを保持することが出来ます。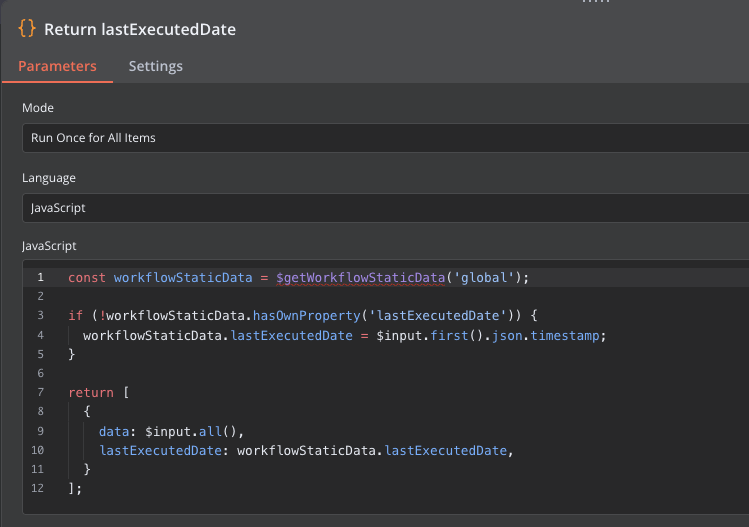
Mastra の Workflow を実行する
Mastra では workflow を実行するための API がいくつか用意されていますが、結果を受け取るまで待つために
/startAsync を使います。runId が必須なので先に /createRun を実行します。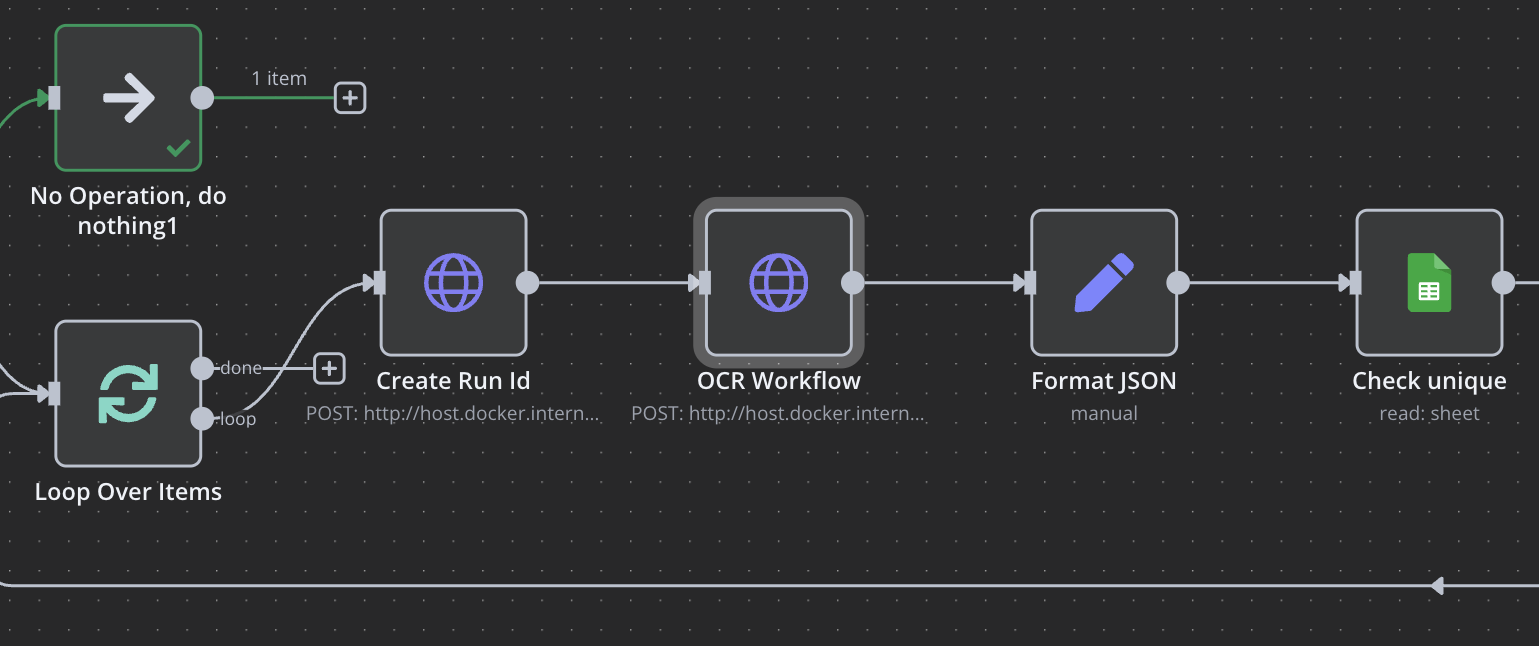
Google Spreadsheet に書き込む
Google Spreadsheet に書き込むためのノードも用意されているのでそれを使います。
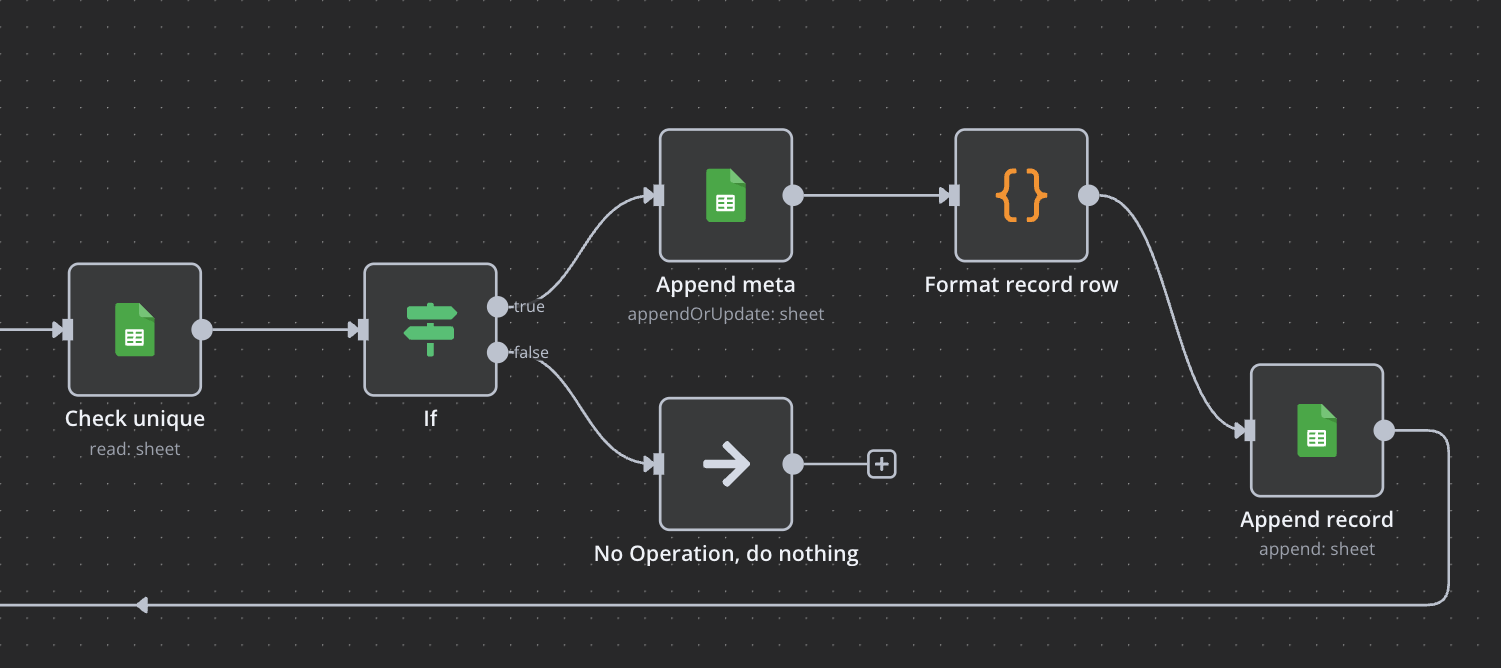
単純に 1 行だけ書き込むなら簡単なのですが、配列をループさせて複数行書き込むには事前にデータを整形しなければなりません。
key 名は Spreadsheet のヘッダーと同じにしておく必要があります。
この辺は普通にコード書いたほうが楽ですね...
const data = $('Format JSON').first().json.data
const result = []
for (const menu of data.menu) {
for (const record of menu.records) {
result.push({
date: $input.first().json['日付'],
name: menu.name,
nameSource: menu.nameSource,
set: record.set,
weight: record.weight,
count: record.count,
text: record.text,
isSuspected: record.isSuspected
})
}
}
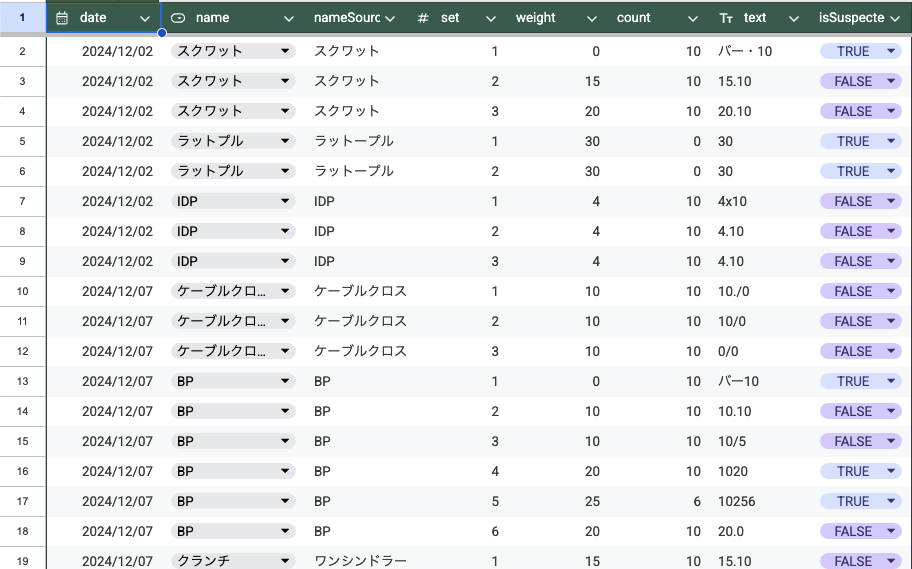
return result実際に書き込まれた Spreadsheet は以下のような感じです。
Meta
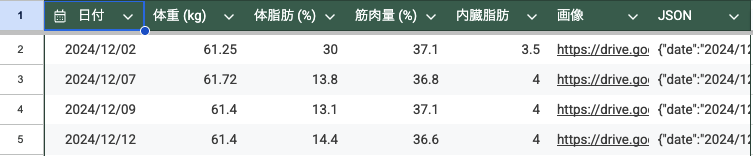
Record
さいごに
自動化は出来ましたが OCR 精度はまだまだ改善の余地があるので引き続き色々試してみたいと思います。